Here at Cockroach Labs, we’ve had a continual focus on improving performance and scalability. To that end, our 2.1 release includes a brand-new, built-from-scratch, cost-based SQL optimizer. Besides enabling SQL features like correlated subqueries for the first time, it provides us with a flexible optimization framework that will yield significant performance improvements in upcoming releases, especially in more complex reporting queries. If you have queries that you think should be faster, send them our way! We’re building up libraries of queries that we use to tune the performance of the optimizer and prioritize future work.
While as an engineer, I’m eager to dive right into the details of how our new optimizer works (TL;DR - it’s very cool stuff), I need to first set the stage. I’ll start by explaining what a cost-based SQL optimizer is, and then tell you the story of how we decided we really, really needed one of those. Enough that we took 4 engineers, shut them into a windowless Slack room, and gave them carte blanche to rewrite a major component of CockroachDB. After story time, I’ll move onto the really interesting stuff, giving you a peek “under the hood” of the new optimizer. A peek will have to suffice, though, as digging deeper will require more words than one blog entry can provide. But do not despair; future articles will delve further into optimizer internals, so stay tuned.
What is a SQL optimizer anyway?
A SQL optimizer analyzes a SQL query and chooses the most efficient way to execute it. While the simplest queries might have only one way to execute, more complex queries can have thousands, or even millions, of ways. The better the optimizer, the closer it gets to choosing the optimal execution plan, which is the most efficient way to execute a query.
Here’s a query that looks deceptively simple:
SELECT * FROM customers c, orders o WHERE c.id=o.cust_id AND c.name < ’John Doe’
I won’t bore you (or me) with the exhaustive list of questions that the optimizer must answer about this query, but here are a few to make my point:
- Should we evaluate the name filter before the join or after the join?
- Should we use a hash join, merge join, or a nested loop join with an index (called a “lookup join” in CockroachDB)?
- If a lookup or hash join, should we enumerate customers and then lookup orders? Or enumerate orders and then lookup customers?
- If there’s a secondary index on “name”, should we use that to find matching names, or is it better to use the primary index to find matching ids?
Furthermore, it’s not enough for the optimizer to answer each of these questions in isolation. To find the best plan, it needs to look at combinations of answers. Maybe it’s best to use the secondary index when choosing the lookup join. But, if a merge join is used instead, the primary index may be better. The optimal execution plan depends on row counts, relative performance of the various physical operators, the location and frequency of data values, and … a lot of other stuff.
Heuristic vs. cost-based
So how do optimizers choose among so many possible execution plans? People have been thinking and writing about that longer than I’ve been alive, so any answer’s going to be inadequate. But, it’s still valuable to discuss two common approaches to the problem.
The first approach is what everyone who builds an optimizer for the first time takes. They come up with preset heuristic rules based on general principles. For example, there might be a heuristic rule to always use a hash join instead of a nested loop join if an equality condition is present. In most situations, that will result in a better execution plan, and so it’s a good heuristic. An optimizer based on rules like this is called a heuristic optimizer.
However, static heuristic rules have a downside. They work well in most cases, but they can fail to find the best plan in other cases. For example, a lookup join loops over rows from an outer relation and looks for inner rows that match by repeatedly probing into an index over the inner relation. This works well when the number of outer rows is small, but degrades as that number rises and the overhead of probing for every row begins to dominate execution time. At some cross-over point, a hash or merge join would have been better. But it’s difficult to devise heuristics that capture these subtleties.
Enter the cost-based optimizer. A cost-based optimizer will enumerate possible execution plans and assign a cost to each plan, which is an estimate of the time and resources required to execute that plan. Once the possibilities have been enumerated, the optimizer picks the lowest cost plan and hands it off for execution. While a cost model is typically designed to maximize throughput (i.e. queries per second), it can be designed to favor other desirable query behavior, such as minimizing latency (i.e. time to retrieve first row) or minimizing memory usage.
At this point, you may be thinking, “but what if that cost model turns out to be wrong?”. That’s a good question, and it’s true that a cost-based optimizer is only as good as the costs it assigns. Furthermore, it turns out that the accuracy of the costs are highly dependent on the accuracy of the row count estimates made by the optimizer. These are exactly what they sound like: the optimizer estimates how many rows will be returned by each stage of the query plan. This brings us to another subject of decades of research: database statistics.
The goal of gathering database statistics is to provide information to the optimizer so that it can make more accurate row count estimates. Useful statistics include row counts for tables, distinct and null value counts for columns, and histograms for understanding the distribution of values. This information feeds into the cost model and helps decide questions of join type, join ordering, index selection, and more.
(Re)birth of an optimizer
CockroachDB started with a simple heuristic optimizer that grew more complicated over time, as optimizers tend to do. By our 2.0 release, we had started running into limitations of the heuristic design that we could not easily circumvent. Carefully-tuned heuristic rules were beginning to conflict with one another, with no clear way to decide between them. A simple heuristic like:
“use hash join when an equality condition is present”
became:
“use hash join when an equality condition is present, unless both inputs are sorted on the join key, in which case use a merge join”
near the end, we contemplated heuristics like:
“use hash join when an equality condition is present, unless both inputs are sorted on the join key, in which case use a merge join; that is, except if one join input has a small number of rows and there’s an index available for the other input, in which case use a lookup join”
Every new heuristic rule we added had to be examined with respect to every heuristic rule already in place, to make sure that they played nicely with one another. And while even cost-based optimizers sometimes behave like a delicately balanced Jenga tower, heuristic optimizers fall over at much lower heights.
By the last half of 2017, momentum was growing within Cockroach Labs to replace the heuristic optimizer that was showing its age. Peter Mattis, one of our co-founders, arranged to have an outside expert on database optimizers run a months-long bootcamp, with the goal of teaching our developers how state-of-the-art optimizers work, complete with homework assignments to read seminal papers on the subject. In order to kickstart discussion and momentum, Peter created a cost-based optimizer prototype called “opttoy”, that demonstrated some of the important concepts, and informed the production work that followed.
By the time I joined the company in early 2018, the company had come to the collective decision that it was now time to take the next step forward. Given my background and interest in the subject, I was tasked with leading a small (but highly motivated) team to build a cost-based optimizer from scratch. After 9 months of intense effort, our team is releasing the first version of the new optimizer as part of the CockroachDB 2.1 release. While there’s still much more we can (and will) do, this first release represents an important step forward. Here are a couple of important new capabilities that the 2.1 cost-based optimizer supports:
- Correlated subqueries - these are queries that contain an inner subquery that references a column from an outer query, such as in this example:
SELECT * FROM customers c WHERE EXISTS ( SELECT * FROM orders o WHERE o.cust_id = c.id )Optimizing correlated subqueries is another blog post all on its own, which I hope to cover in the future.
- Automatic planning of lookup joins: When deciding how to execute a join, the optimizer now considers lookup joins, in addition to merge and hash joins. Lookup joins are important for fast execution of equality joins, where one input has a small number of rows and the other has an index on the equality condition:
SELECT COUNT(*) FROM customers c, orders o WHERE c.id=o.cust_id AND c.zip='12345' AND c.name='John Doe'
Here, the optimizer would consider a plan that first finds customers named “John Doe” who live in zip code “12345” (likely to be a small number of rows), and then probes into the orders table to count rows.
Under the Hood
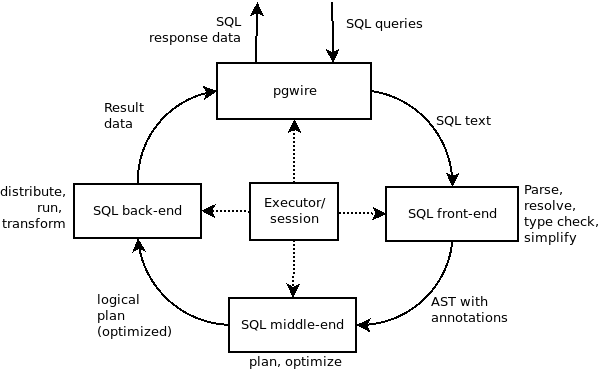
As promised, I want to give you a quick peek under the hood of the new optimizer. To start, it’s useful to think of a query plan as a tree, with each node in the tree representing a step in the execution plan. In fact, that’s how the SQL EXPLAIN statement shows an execution plan:

This output shows how the unoptimized plan would execute: first compute a full cross-product of the customers and orders tables, then filter the resulting rows based on the WHERE conditions, and finally compute the count_rows aggregate. But that would be a terrible plan! If there were 10,000 customers and 100,000 orders, then the cross-product would generate 1 billion rows, almost all of which would simply be filtered away. What a waste.
Here’s where the optimizer proves its worth. Its job is to transform that starting plan tree into a series of logically equivalent plan trees, and then pick the tree that has the lowest cost. So what does “logically equivalent” mean? Two plan trees are logically equivalent if they both return the same data when executed (though rows can be ordered differently if there is no ORDER BY clause). In other words, from a correctness point of view, it doesn’t matter which plan the optimizer picks; its choice is purely about maximizing performance.
Transformations
The optimizer does not generate the complete set of equivalent plan trees in one step. Instead, it starts with the initial tree and performs a series of incremental transformations to generate alternative trees. Each individual transformation tends to be relatively simple on its own; it is the combination of many such transformations that can solve complex optimization challenges. Watching an optimizer in action can be magical; even if you understand each individual transformation it uses, often it will find surprising combinations that yield unexpected plans. Even for the relatively simple query shown above, the optimizer applies 12 transformations to reach the final plan. Below is a diagram showing 4 of the key transformations.
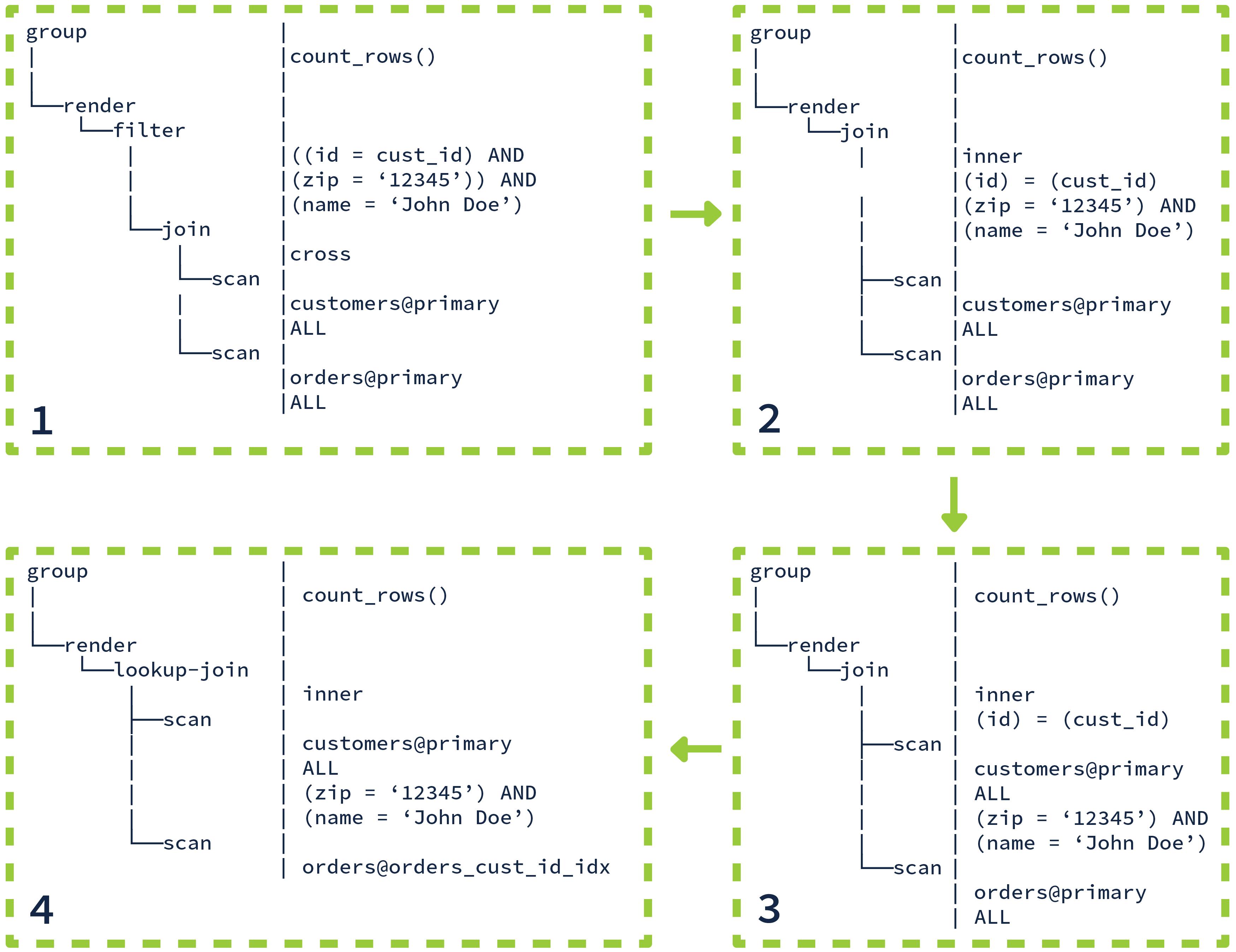
You can see that the filter conditions get “pushed down” into the join and then become part of the scan operator for maximum performance. During the final transformation, the optimizer decides to use a lookup join with a secondary index to satisfy the query.
As of this writing, the cost-based optimizer implements over 160 different transformations, and we expect to add many more in future releases. And because transformations lie at the heart of the new optimizer, we spent a lot of time making them as easy as possible to define, understand, and maintain. To that end, we created a domain specific language (DSL) called Optgen to express the structure of transformations, along with a tool that generates production Go code from that DSL. Here is an example of a transformation expressed in the Optgen language:
[MergeSelectInnerJoin, Normalize] (Select $input:(InnerJoin $left:* $right:* $on:*) $filter:* ) => (InnerJoin $left $right (ConcatFilters $on $filter) )
This transformation merges conditions from a WHERE clause with conditions from the ON clause of an INNER JOIN. It generates ~25 lines of Go code, including code to ensure that transitively matching transformations are applied. A future blog post will delve into more Optgen specifics, as there’s a lot there to cover. If you can’t wait for that, take a look at the documentation for Optgen. You might also take a look at some of our transformation definition files. If you’re especially ambitious, try your hand at crafting a new transformation that we’re missing; we always welcome community contributions.
The Memo
I’ve explained how the optimizer generates many equivalent plans and uses a cost estimate to choose from among them. That sounds good in theory, but what about the practical side of things? Doesn’t it take a potentially exponential amount of memory to store all those plans? The answer involves an ingenious data structure called a memo.
A memo is designed to efficiently store a forest of plan trees for a given query by exploiting the significant redundancies across the plans. For example, a join query could have several logically equivalent plans that are identical in all ways, except that one plan uses a hash join, another uses a merge join, and the third uses a lookup join. Furthermore, each of those plans could in turn have several variants: in one variant, the left join input uses the primary index to scan rows, and in another variant it uses a secondary index to do the equivalent work. Encoded naively, the resulting exponential explosion of plans would require exponential memory to store.
The memo tackles this problem by defining a set of equivalence classes called memo groups, where each group contains a set of logically equivalent expressions. Here is an illustration:
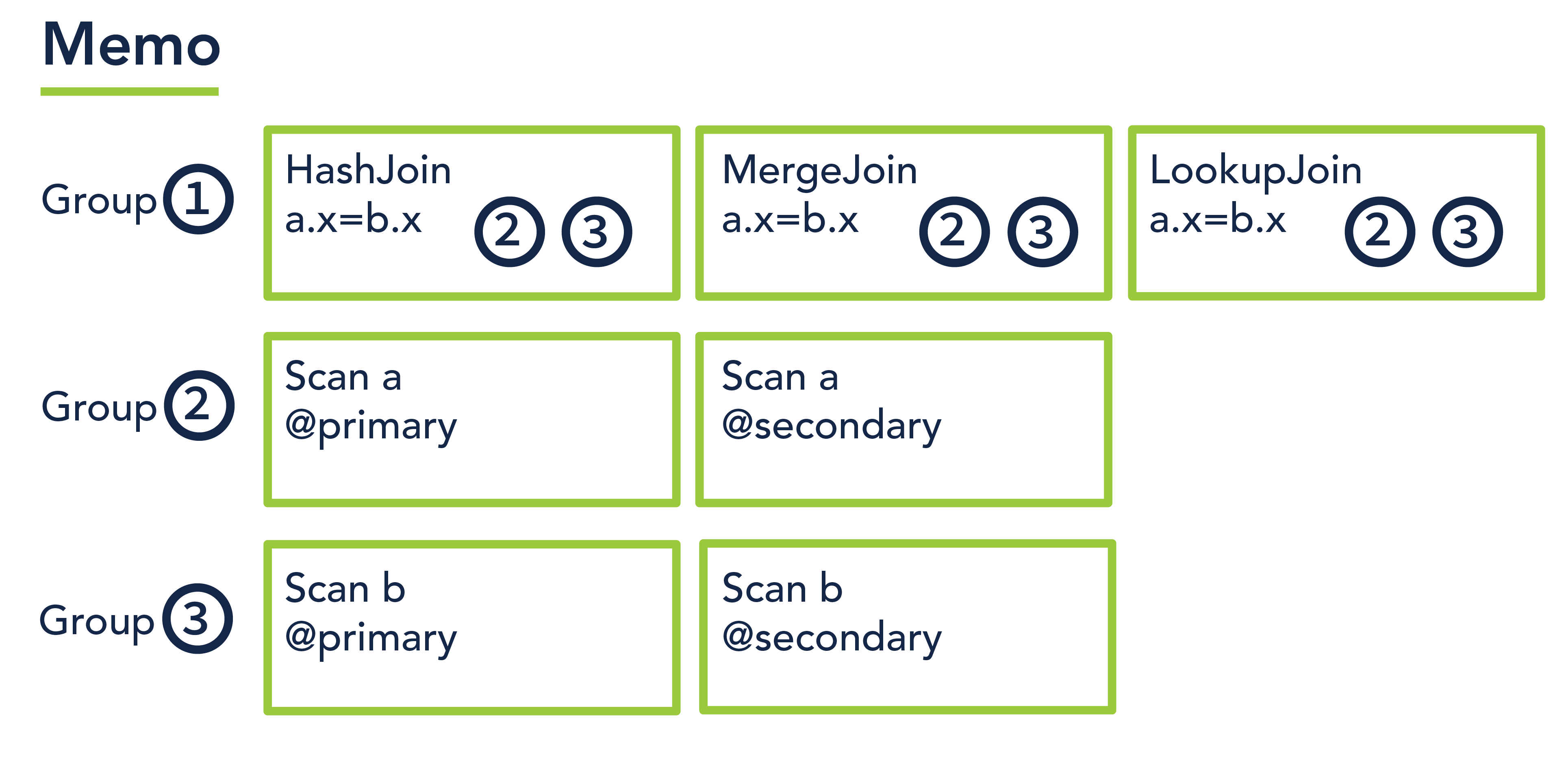
To build a plan, pick any operator from group #1, then pick its left input from group #2 and its right input from group #3. No matter which you pick, you have a legal plan, since operators in the same group are guaranteed to be logically equivalent. Simple arithmetic reveals that there are 12 possible plans (3 * 2 * 2) encoded in this memo. Now imagine a complex reporting query with a 6-way join, complex aggregation, and lots of filter conditions. The number of plans might number in the thousands, and yet would be encoded in much less space than you would expect if you weren’t aware of the memo structure.
Of course the optimizer does not just randomly pick one of the possible plan trees from the memo. Instead, it tracks the lowest cost expression in each memo group, and then recursively constructs the final plan from those expressions. Indeed, the memo is a beautiful data structure, reminding me of the illuminati diamond ambigram from Dan Brown’s novel “Angels and Demons”. Both encode more information than seems possible.
Conclusion
Our team plans to make future blog posts on the internals of the cost-based optimizer in CockroachDB. I’ve only scratched the surface in this post. Let us know if you’d like us to cover specific topics of interest to you. Or even better, come join Cockroach Labs, and help us build a planet-scale ACID database.
And if building a distributed SQL engine is your jam, then good news — we're hiring! Check out our open positions here.